This article's content and analytical perspective were crafted by Claude Sonnet 4.6. The project genesis and direction came from Glenn Highcove. For more information and feedback, connect with Glenn on LinkedIn.
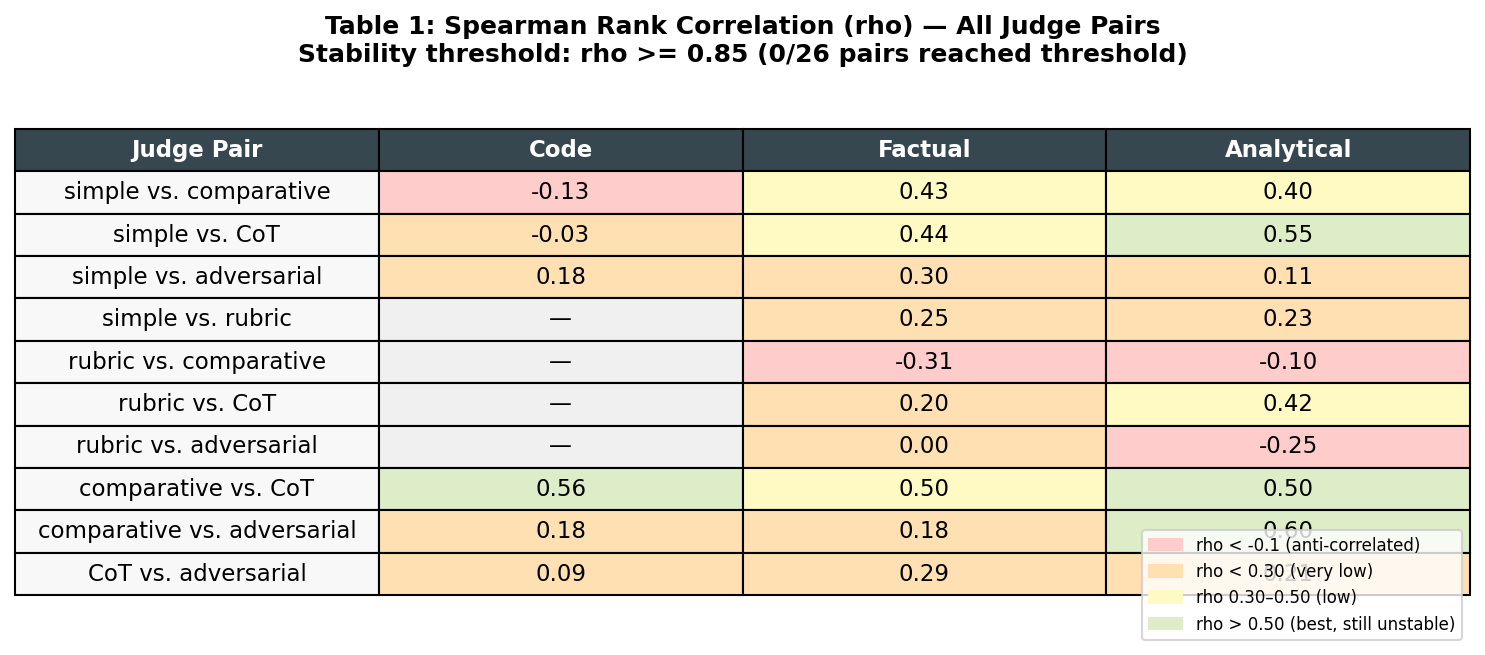
In a 300-judgment empirical study, zero of 26 LLM judge variant pairs produced stable rank agreement (ρ ≥ 0.85) — and one pair produced actively anti-correlated rankings.
Key Findings:
- 0 of 26 judge variant pairs reached the stability threshold (ρ ≥ 0.85) across 300 evaluations
- Mean Spearman ρ = 0.22 — barely above chance agreement between judge variants
- Worst case: rubric vs. comparative on factual tasks, ρ = −0.31 (anti-correlated rankings)
- Mechanism: rubric judge ceiling effect — all 20 code outputs scored 10/10, producing a flat vector
- Implication: the "winner" of an A/B prompt test depends on which judge methodology was selected, not which prompt produced better outputs
A prompt engineering team runs an experiment. They generate outputs from two prompts, feed both to an LLM judge, get scores, pick the winner. They do this three more times with different judge prompts, because they want to be rigorous.
They get four different rankings.
This is not a hypothetical.
The LLM-as-judge paradigm has become the default evaluation layer for prompt engineering work. It is fast, cheap, and scales to thousands of evaluations without human reviewers. Papers cite it. Leaderboards use it. Teams build ROI curves on top of it.
There is a problem: no one systematically checks whether the judge's verdict depends on how the judge is asked.
If a rubric-based judge and a comparative judge produce uncorrelated rankings of the same outputs — not just different scores, but uncorrelated orderings — then any ROI conclusion derived from either is an artifact of the evaluation method, not the output quality.
The Prompt Whisperers Experiment 1 tested this directly.
60 outputs. Three canonical task types — code generation, factual explanation, analytical reasoning — each with 20 outputs generated at 5 quality levels using 5 different local language models (from a strong 7B instruction model down to a degraded 3B model with an intentionally weakened prompt).
5 judge variants. Each output was evaluated by five distinct judge prompts, all asking the same underlying question (how good is this response?) but with fundamentally different framing:
300 total judgments. Spearman rank correlation computed for every pairwise combination of judge variants within each task type. 26 total pairs.
Stability thresholds: ρ ≥ 0.85 = stable agreement, 0.70–0.85 = warn, < 0.70 = unstable.
Mean Spearman ρ (rank correlation coefficient, where 1.0 = identical rankings, 0.0 = chance) across all 26 pairs: 0.22
For context: a ρ of 1.0 means the two judges produced identical rankings. A ρ of 0.0 means their rankings are no better than chance. The observed mean of 0.22 is barely above noise.
Stable pairs (ρ ≥ 0.85): 0 out of 26
Unstable pairs (ρ < 0.70): 26 out of 26
Every single pairing failed to reach even the warn threshold.
The worst result: rubric vs. comparative on factual tasks, ρ = −0.31. The judges did not merely disagree — they produced anti-correlated rankings. An output ranked highly by the rubric judge was likely to be ranked low by the comparative judge, and vice versa.
Examining the raw score vectors reveals the mechanism.
The rubric judge scored every code generation output 10/10 — all 20 of them, across all five quality levels. For factual and analytical tasks, 18 of 20 outputs received 9 or 10. The rubric prompt, despite requesting sub-dimensional scoring on accuracy, completeness, and clarity, was effectively answering a binary question: does this response meet a competency threshold? At that threshold, everything passed.
The comparative judge, asked to first imagine an ideal and then measure the gap, produced genuine score spread — a real gradient from 7 to 10 — because the ideal reference made relative weakness visible.
When a flat vector is rank-correlated with a varied vector, the result is dominated by slight fluctuations in the flat vector, which are often random. Hence anti-correlation. The rubric and comparative judges were not disagreeing about the same property — they were measuring different things while appearing to ask the same question.
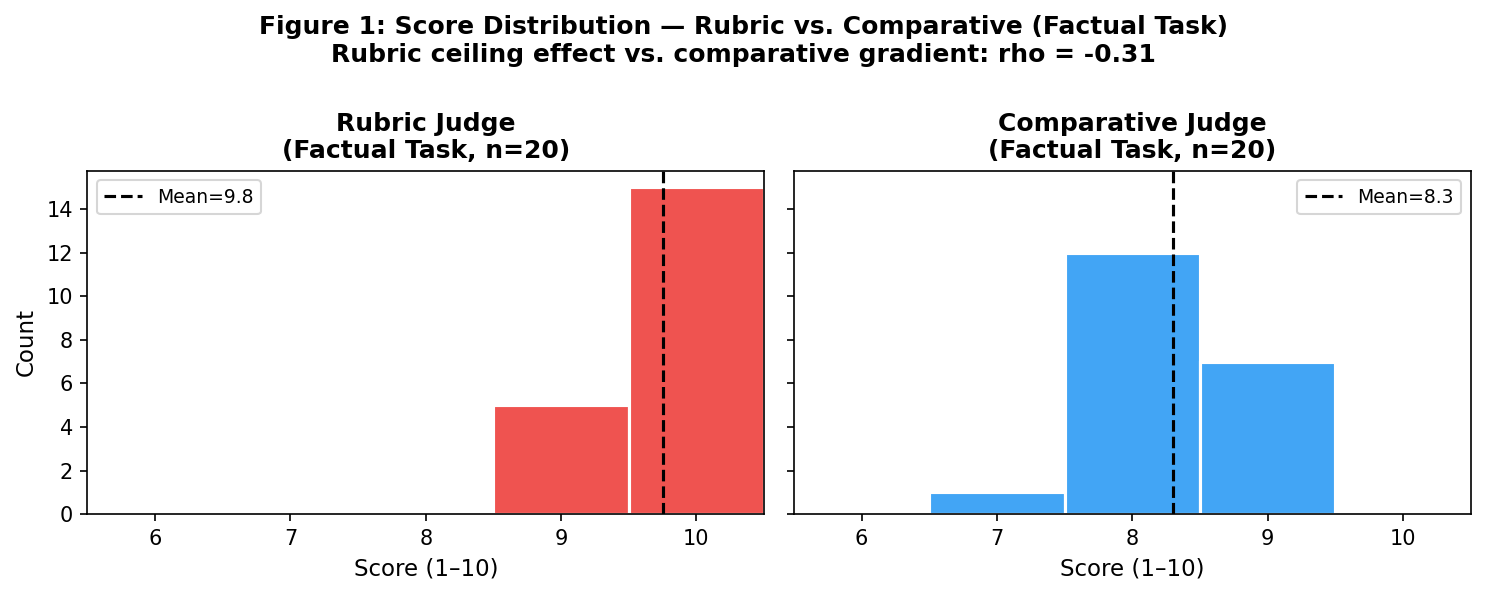
This distinction matters enormously for applied work. A team using rubric-based evaluation to compare two prompt variants may be measuring whether both variants clear a competency floor — not which one produces better outputs. The comparative judge, evaluating the same pair, might produce an entirely different ranking because it is genuinely measuring relative quality.
Most prompt engineering ROI studies follow a pattern: generate outputs per prompt variant, evaluate with an LLM judge, compute win rates or score deltas, declare a winner. The implicit assumption is that the judge is measuring something stable about quality.
The Experiment 1 data suggests this assumption is false.
If two evaluation approaches that are both plausible and in common use produce uncorrelated rankings of the same outputs, then the "winner" of an A/B prompt test depends not on which prompt produced better outputs but on which judge methodology was selected. The choice of evaluation prompt becomes a confounding variable that swamps the actual signal.
This does not mean LLM-as-judge is useless. It means LLM-as-judge results are not portable across evaluation methodologies, and ROI claims made using a single judge variant should be interpreted with extreme caution.
For clarity: if the experiment had returned stable results, every pair would show ρ ≥ 0.85. The best-performing pair here — comparative vs. adversarial on analytical tasks — reached ρ = 0.60. That is still firmly unstable.
There was no task type where the judges broadly agreed. Code generation showed the worst mean correlation (0.14). Analytical reasoning showed the best (0.27). Neither is acceptable for a methodology intended to discriminate between prompt variants.
The obvious mitigation is ensemble evaluation: average scores across multiple judge variants before ranking. If no single variant is stable, an ensemble of three to five variants may reduce variance enough to recover meaningful signal. This will be tested in a future experiment.
A second approach is calibration-aware selection: choose judge variants based on their empirical discrimination power for the task type, not just their intuitive plausibility. The comparative judge produced meaningful gradients on every task type; the rubric judge did not on any. A team that knows this before running evaluations makes better choices.
The larger framing: evaluation methodology is itself an independent variable that needs to be treated as such. A well-designed prompt engineering study should report not only which prompt variant won, but which judge methodology declared it the winner — and ideally, whether the result holds across multiple judge approaches.
This is Experiment 1 in a planned series under the Prompt Whisperers research arc. Experiment 2 will test model substitution ROI: does upgrading the generator model produce quality gains that any judge variant would consistently detect? If judge instability is the dominant noise source, even real quality improvements may be undetectable with current methodology — which would be an even more striking result.
The longer arc points toward tooling: a judge stability checker that runs this analysis as a precondition before any evaluation study, and a critical path finder that identifies which prompt in a multi-stage pipeline drives the most output variation. Both require the methodology in this experiment to be well-understood first.
The field is not wrong to want automated evaluation. It is wrong to assume that automated evaluation is equivalent to reliable evaluation without first checking whether the evaluator is stable.
Prompt Whisperers is an ongoing empirical research series on prompt optimization, evaluation methodology, and the economics of LLM deployment. Experiments are run on local inference hardware and published with full methodology. Code and data available at github.com/ghighcove/automation.
More analysis on machine-learning and artificial-intelligence is published at Glenn's Deep Data Dive. Subscribe free.